Community Wishlist/Wishes/Wikipedia Machine Translation Project
Description
Machine translation is getting better and better, it is far from perfect but at least for some language pairs, machine translations of full texts of Wikipedia articles are soon approximating flawlessness. They still have errors – often many of them – but keep in mind they 1) will keep getting increasingly better over the years and 2) one could create ways for post-machine-translation error correction & adjustment (described at bottom and key part of this proposal).
I don't think anything else could increase Wikipedia readership and the comprehensiveness of articles available to people in their own language nearly as much as this – I hope outlining it here and now is a step towards making it a reality. It would supercharge contributions, making content far more widely available, make Wikipedia content read more in the non-anglophone world, and make translation work much more efficient. This proposal is summarized in this diagram:
The problems addressed here or why this is needed

- Most Wikipedias have far fewer articles than English Wikipedia. In addition, the quality or comprehensiveness is usually significantly lower.
- The translations don't need to be based on only English Wikipedia (ENWP) – other Wikipedias could also be used as the base text, mainly for subjects specific to some country/language.
- For example this study found that even the most extensive language editions only cover about one-third of the climate change-related articles that ENWP has.
- Other Wikipedias are usually not as up-to-date as ENWP or the WP that is specific to the subject.
- For manually translated articles, changes are not synced to the other languages Wikipedia. That is regardless whether or not machine translation was used for translation of course: when the source article changes then these changes are not also made to the other language(s) Wikipedia(s). Articles get expanded with missing info, updated with newer info, overhauled, or restructured all the time.
- For example, I wrote an article in ENWP then translated it to create a new German-language article; then some time later extensively edited the English WP article but these changes are now missing in the German article.
- Manually translating articles is not very fulfilling as a volunteer activity – there are probably exceptions but most people like to rather write new things. For any language Wikipedia, there are countless of important notable articles that haven't been created but could have just been translated from ENWP.
- Semi-manual translation is slow & will remain very incomplete – it's not done at a comparable scale and it's clear that people aren't translating articles at a scale and rate that would make other Wikipedias as comprehensive as ENWP. This isn't even the case for the largest languages like Spanish or German WPs which lack articles on sections on major topics that are in ENWP. Even if some Wikipedia achieved an article count approximating ENWP's by using up a very large amount of volunteer time for semi-manual translation, these articles would quickly become outdated and not stay in sync with their source article.
- Smaller articles/Wikipedias are not as much monitored, edited, read and checked as ENWP so there's a greater likelihood of issues in these, including more bias.
- Often, there is no article for a subject in a person's language – a machine translated version of the best or EN Wikipedia article on it is usually better than having no such article as an option. The user will be made aware that it's machine translated. This also means greater reach since content on ENWP can now be accessed also by those reading or searching the Web in other languages, making contributions more worth the effort and increasing free knowledge.
- For subjects for which a language's Wikipedia has an article, that article may be extremely short or in a miserable state while another WP, usually ENWP, has a good-quality comprehensive article on it. ENWP articles are usually much more comprehensive. In such cases the reader may seek to or benefit from also opening the machine-translated version. This also applies in general: people only have an extra option, they can and will still read their native language Wikipedia. For example, some could see value in having a shorter article and having it 100% flawless while other readers at least on a case-by-case basis may prefer a more comprehensive article translated from English Wikipedia to their language even if it contains two or three minor mistranslations. They would see the MTWP article in their Web search engine when searching for a subject in their own language or switch to it if they find no or a only a too-short article exists in their language Wikipedia.
This is a proposal to improve internationalization/multilingualism and open knowledge and probably not only ENWP would be used as source despite that machine translation currently works best for that language and that ENWP is the global Wikipedia (possible exceptions: lang/country-specific subjects, cases where quality is much better in another language, a subset of cases where no ENWP article exists).
Third-party implementation
Here is a key consideration: if the Wikimedia movement does not set up such a project I think at some point some external actor or organization will do so and it's better if we as Wikimedians set it up. For example, then we can participate in decisions, better guarantee neutrality, contribute to the module described below, and so on and it could integrate better with Wikipedia such as via an extra button in the Languages dropdown of articles.
Wikipedias' text contents are CC BY-SA – I think this is more a question of when and how it will be done than a question of whether it will be.
Post-machine-translation error correction module
The machine translated pages would not be editable in the normal way (so articles are not forked once the machine translated article is set up) – instead, these articles change whenever the source article changes (or a short while thereafter) so they are in sync. This means they are only ever outdated by for example 1 month assuming the source article was edited during that time. People can only improve the translation (so-called post-editing), so they can't remove or add parts but just adjust the translation (any semantic changes would need to be done in the source article). The key thing is that corrections are also automatically applied after the source article has changed and the translated article is updated (which could happen for example monthly if the source article has been modified).
- Tools like DeepL and Google Translate don't convert wikilinks or citation templates. This system could be built so it understands/uses wikitext markup and Wikipedia templates.
- If a wikilink's article exists in the target language instead of translating the words, it could use the title of that article in the target language.
- It could convert citation templates to that language's Wikipedia citation template. For example,
last1=in en:Template:cite journal equates toapellidos=in es:Plantilla:Cita publicación - The wikitext makes it harder for machine translation tools to translate text – currently either there are more errors initially or the user has to first remove the wikitext / copy-paste the text without the wikitext and remove things like
[1][2]. With a streamlined Wikipedia machine translation system, the wikitext would be removed/ignored for the resulting machine translation.
- As noted earlier, there often are mistranslations – with the roughly envisioned system:
- one would fix these once and then when the translated article gets updated because the WP article was changed, it keeps these previous corrections (either as is via recognizing the phrase or by 'remembering' the change made previously and applying it anew to the changed sentence)
- there likely are further things one can do with such a system such as via greater use of novel AI NLP models such as letting these improve the translations (see this study) and translating with all the different languages Wikipedia articles as a virtual context to improve the quality of translation, for example to correctly translate ambiguous words (see phab:T155847)
- most errors are only 'instances' of a general flaw (common errors/issues) so many of these errors could be fixed at once or marked for likely-error in rule-type ways
- For example, in this study human evaluation of translated texts was used for systematically identifying various issues with MT outputs. For example there can be errors in the source text or ambiguous parts whose correct translation requires common sense-like semantic language processing or context.
- In this paper it is noted that Machine translation researchers might find opportunities to expand the models available to Wikipedians for translating articles into their language. – what is proposed here may be of interest to organizations and researchers who could greatly benefit via collaboration and from the collective intelligence of Wikimedias identifying translation errors, improving the overall state of machine translation which in turn improves the state of the MTWP.
- Whenever a correction is made, the mistranslation could get registered so more instance of that error in other articles get at some point 'marked' so they can get fixed at scale, improving the overall site's quality of translations (note: that there are some spelling errors in the largest Wikipedias does not make the sites useless, the same applies here to a different extent and the sooner work on this starts the better I think). Some may get automatically corrected while some phrases are just flagged for human checking.
Basically, when you use machine translation and make corrections, if these are transparent they can be used to improve the MT overall and change similar cases or flag them for human review. One can also use two different machine translation and then use the diff to let the user decide which is better or if it needs to be changed as a support for machine translation. For example, for these subtitles I used two different MT tools and then edited the result using the diff. One 'mistake' that one can fix with systematic transparent correction is that large numbers like 96 should be translated as numbers, not "sechsundneunzig" in this case – one would make a MT rule for that so that large numbers are always translated like so when numeric in the source article, and such can also be identified implicitly by learning from all the transparent adjustments people do.
This should also make it clearer why having these articles published in discoverable static websites is key here. This is very different from just letting Google Translate dynamically translate an article (which most people don't use anyway). This wouldn't be implemented by having millions of MT articles published in a separate/sub-site at once for ~300 languages – it would be implemented gradually and be done only for language pairs where machine translation works good enough.
If it's possible for the translator tool / MinT to specify 'low confidence for correct translation' for phrases (e.g. because some of its words have ambiguous meanings where both meanings would make sense in the context so the certainty that it's been translated correctly is low) then these would be phrases flagged for needing review as well. MTWP contributors would have special interfaces of which one enables them to quickly go through many flagged phrases.
Checking and/or checking of flagged phrases in a machine translated article of an article the user recently edited / edited a lot / is interested in could become a task type of the tasks dashboard suggested in related wish Suggested tasks based on contributions history (user interests) also for experienced editors. For example, if one has configured languages German and English (or has lots of contributions in both Wikipedias if langs aren't configured), and has recently edited ENWP article X then checking the machine translated German version of article X would show up in the tasks, if clicked one would jump from one flagged phrase needing review to the next with a split view where the EN version is on the left and the DE version on right. Once all flagged phrases have been adjusted/corrected, the user can review the overall article to potentially spot any unflagged issues.
Moreover, media can in this post-machine-translation editing processes also get switched out for translated media, e.g. videos redubbed to other languages or translated versions of charts (this could partly but not fully be done automatically for files where other language versions have been specified in the |other_versions= field on Wikimedia Commons or Wikidata).
A new Wikimedia project or a project to add a big feature? Next steps
Maybe this will turn into a new project proposal, if you are interested in this please comment/sign up on the talk page since this needs a collective effort, including the involvement of developers, researchers, and editors.
I'm not affiliated with Google, DeepL or alike (also a modular approach would probably be best and maybe MinT could be used). This project would be a large boost for the public domain, free knowledge and global education and make us all far more productive. It would help ensure the Wikimedia projects benefit from AI rather than only the other way around.
It sounds similar to recently approved Abstract Wikipedia in that In Abstract Wikipedia, people can create and maintain Wikipedia articles in a language-independent way but it is very different. Abstract Wikipedia will not have lengthy Wikipedia articles roughly matching depth and quality of the ENWP article. Even if it would do so (and it doesn't seem to be the goal of the project) then that doesn't mean other approaches can't be implemented alongside it it wouldn't have millions of articles. Again, it's not feasible to have long articles roughly as long as the ENWP article with Abstract Wikipedia. That this project exist shouldn't be a stopgap to other ways to increase Wikipedia's reach/impact/coverage and innovation.
Maybe it would not become a separate project and is implemented more as a kind of 'feature' or part of Wikipedia but I think in any case a separate site would probably be best. If it will or would have to become a new Wikimedia project, there could be changes on the standard Wikipedia side as well, such as displaying the links in the language dropdown of articles.
Here are some more relevant datagraphics:
-
 List of Wikipedia articles by language
List of Wikipedia articles by language -
 Most popular edition of Wikipedia by country
Most popular edition of Wikipedia by country -
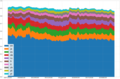 Wikipedia page views by language
Wikipedia page views by language -
 Wikipedia editors by language over time
Wikipedia editors by language over time -
 Wikipedia article depth (collaborativeness indicator)
Wikipedia article depth (collaborativeness indicator) -
 Included images by language
Included images by language






Assigned focus area
Unassigned.
Type of wish
Feature request
Related projects
Wikipedia
new project
Affected users
Mainly Wikipedia readers that do not prefer reading Wikipedia in English
Other details
- Created: 19:05, 27 July 2024 (UTC)
- Last updated: 03:46, 18 November 2024 (UTC)
- Author: Prototyperspective (talk)