Research talk:Wikipedia Gender Inequality Index
Key links
editHere are links to our ongoing work:
Sources
editI'm not sure the title describes what you're going to measure. You're not going to measure "Wikipedia inequality", that is inequality intrinsic to Wikipedia itself, unless you compare it to the sources. --Nemo 10:19, 24 June 2014 (UTC)
- @Nemo bis: You are right; our goal is not so much to measure the inequality intrinsic to Wikipedia, but rather, how gender inequality changed through history, using Wikipedia data. Nonetheless I do think that we can shed light on the Wikipedia-inequality as well, although I think that due to our focus not on editors but Wikipedia content we will focusing on a different aspect of it (to this day, majority of the discussions on Wikipedia's gender inequality focused on the 80/20 split in the editor base). --Piotrus (talk) 06:59, 23 October 2014 (UTC)
Emails
editJuly discussion "Gender Inequality Index Notes"
editThis discussion concerned the early and now partially obsolete first draft / lit review of the paper
i nationality/citizenship -
this can be tricky for historical figures since sometimes nations change. for instance in this paper (http://arxiv.org/abs/1405.7183) Kant is Russian, because where he lived is now Russia. I think its the wrong way to handle it. Also I think with Wikidata "as of" qualifiers we can make it historically accurate. -MK
Nationality/citizenship will certainly have a degree of error. I was also told on wikidata they prefer not to add it at this point to avoid controversies, so I think most controversial bios will have no parameter. Still, I hope we can get some data on it. Reading https://blog.wikimedia.org/2014/06/29/research-newsletter-june-2014/#.22Interactions_of_cultures_and_top_people_of_Wikipedia_from_ranking_of_24_language_editions.22 I think you make an interesting point about wikidata, but keep in mind it often takes 2+ years for a paper to get published (that's my average...). So I wouldn't be surprised if they finished their research BEFORE wikidata even existed.- PK
Yeah, maybe I was too harsh ;) -MK
"The authors make mention that maleness does decrease over time as well. " So they did a little on the topic we are discussing, I'll have to review this in more detail. But from what I've seen about their work, we can improve on it, at the very least. Plus, for them it's a side note, for us it will be the major theme. -PK
Certainly we can improve on it, and also make the regression which is a bit more key. -MK
ii
Exogenous metrics.
I think for comparison, and sanity checking it will be important to compare our notions of longevity with other studies (that don't rely on wiki*) -MK
if this fits the article's theme (I am not so sure about it) I'll certainly tie it to some prior research. -PK
iii Article quality assessment
I know a couple of machine learning ways to give a rough quality score to a piece of text. It might be kind of a tough problem, to run it over all the articles in all the languages, but this is a technical problem that I could look into solving. And would kind of be a nice challenge. -MK
iii. quality - could be interesting to try it the way you describe, but the easiest way would be if we could get the corresponding talk page -PK
oh right, that's an alternative too. -MK
iv Perfect Equality
I really like the predictor of when "perfect equality " will be reached. However I imagine we will be attacked on two fronts that we will want literature to back up. (1) is from Gender Studies. Is 50/50 "perfect" equality. Because of non-binary models of gender some people say taht perfect equalty is more like 49/49/2(other). And so we will probably want some academic grounding or definition for "perfect equality". (2) is that another comparison measure would be helpful here. I would like to maybe look at VIAF or library of congress dataset about known authors m/f percentage over time, as a comparison measure. I wonder if there are any other history corpus that we could get this comparison from. (3)this result will give a nice catchy subtitle to our paper especially in social media. "Wikipeida wont reach perfect gender equality until 2160" or whatever. -MK
you are totally right that the perfect equality will have to be cautiously worded. Good point about 49/49/2, and that what we are predicting is a parity with regards to subject biographies, which of course isn't a metric that can account everything. Just a metric, a "fun metric" indeed, but one of many. Hopefully the reviewers and readers will find it fun and publishable :) -PK
Me and Max have agreed to shift our email discussion to here, to be more transparent and to allow interested community members to contribute to our project. First, I will start by including the key points of our past emails. --Piotrus (talk) 07:18, 23 October 2014 (UTC)
September's discussion "csv version 1"
editDiscussion of Google Docs draft
editNot sure where the first question was... - probably in a deleted comment in a draft?
Regarding the question if we can correlate with other indices, I think that's intriguing, but probably for a follow-up paper. Their data is in a different format, and trying to create a composite index merging ours and another one will be quite a challenge, I think. But yes, it's an idea to keep in mind for a follow-up work. For example if you take up grad studies, it would be a great project to work on; heck, you could turn it into a Master or PhD thesis/dissert. -PK
Credit for coning WIKI goes to Max ("how about trying to make the acronym "WIGI" WIki Gender Index." - MK)
The following exchange is about the following paragraph from the early draft:
Research Question 2: what will be the variations by region/country/nationality/ethnicity/religion/language? -PK
this is the only variable i feel is strong enough to make useful data. religion and country are not represented enough in the wikidata, but inferring the existence of a biography from the existence of a site-link (language based) is what we have.-MK
Great. And I think we should have a paragraph discussing why we are not using religion/country/etc., in the study limitations section. I'll copy your sentence there for future c/e.-PK
Excellent, so we are correlating with languages, which in some ways are proxies for countries and cultures.-MK
The following exchange is about the following paragraph from the early draft:
RQ3: are there interesting variations in easy to calculate variables such as subject longevity and article quality? -PK
longevity is possible i think we can even use this script by Markus
The following exchange is about the following paragraph from the early draft:
Common indicators include such as life expectancy, literacy rate, income, and most relevant to us, the number/percentage of high-end political and economic position holders (i.e. professional and technical positions; positions as legislators, senior officials and managers; parliamentary seats, ministerial positions, heads of state), as used by the major indices, with the data being populated by administrative and historical records, as well as national surveys. -PK
IDEA - SHOULD WE TRY TO PRODUCE A SEPARATE INDEX WITH ONLY THOSE MORE CLEARLY DEFINED GROUPS OF INDIVIDUALS? HOW FEASIBLE WOULD THAT BE? Related link: https://en.wikipedia.org/wiki/Category:Positions_of_authority -PK
technically its not that difficult, you just add the contain on the human that they "have profession: X", but im not sure the data is rich enough to give meaningful results if we do add the extra constraints. -MK
Let's see how may we can get for the professions listed " professional and technical positions; positions as legislators, senior officials and managers; parliamentary seats, ministerial positions, heads of state". I am pretty sure we can find corresponding categories easily; and hopefully it wouldn't be difficult to correlate them with our data. The following category is probably a useful start: https://en.wikipedia.org/wiki/Category:Positions_of_authority through as everything, it is work in progress (I've just added "religious leaders to it as it was not categorized within it...). I am not sure at this state whether we should just have a flag if a person is within the subcategory structure of this, or try to differnetiate it further. It would be interesting to compare let's say gender equality within politics, business, religion and such. That said, I suggest we live this on a side while we work on other aspects, but hopefully we will be able to get some usable data here. I guess the main issue is how easy can we correlate https://en.wikipedia.org/wiki/Category:Positions_of_authority with our Wikidata dump file? -PK
Ok, I will work this into the next version of the dump file. -MK
The following exchange is about the following paragraph from the early draft:
Our primary indicator - having a Wikipedia biography - can be seen as conceptually similar to the indicator of a having a high-end political and economic position, and correspondingly, the indicator of number of individuals with a Wikipedia biography per unit of time or region is similar to the number of holders of political and economic positions. -PK
but we are comparing languages not women. So this should be more accurately reframed, "Our primary indicator, what percentage of women or non-males, have a biography in the target language" -MK
I've added "(in a target language)". The non-males is a very interesting point; we need to have some discussion of other genders. Since you wrote some about it, I think you may want to write a paragraph or such about it, perhaps around the discussion of your other findings. We will also have to briefly describe (and decide) how we want to handle other genders... Should be categorize them for now as "third-gender"? I know there are more than one in that group, but since they are not really consistent (or used widely), I'd tentatively suggest to work on four groups: male, female, other, data missing.-PK
I think that "third-gender" means something specific. I wrote to gendergap@wikimedia.org and the UC Berkeley Gender studies department to see if there was any expert that could help with that.-MK
Did you encounter any mentions of non-male-non-female genders in other indexes so far? .-MK
Nope.-PK
You mention later you'd like to aggregate female and other. I think we may want to test three variables: female, other, and f+o. Through based on what you reported earlier, I wonder if we can get any statistically significant data from the other? If we are lucky, we could find (as I expect) that equality for other is lagging behind women. But is the data good enough to support that? We will see... -PK
If we could find numbers for "other" in different indexes, then we could compare and say that they were underrepresented more or less than the female category. -ML
And yes, once we decide on terminology, we will have to change the language. - PK
do all wikipedia language versions have notablility policies? Wikidata's policy is less strict than English Wikipedia's, I know that much. Somebody can be notable if it will just make a family tree graph more complete . I think they call this "structural" notability. -MK
Good question, and something we (I) will describe a bit more. The smaller the wiki, the fewer rules it has, and (I think, but that's just a personal observation that could in fact be a root of an entire new paper), the more inclusive it is. At the very least, I know Polish Wikipedia has much smaller set of notability rules, and is more inclusive. -PK
Yes, so we might actually have more Polish women included that anglo-saxon women. - MK
That is, the notability policies are potentially sexist. -MK
Hmmm. I am totally fine saying strong things, but academic papers should be careful to not have too overreching statements. Plus potentially is a bit of a weasel word. I think we should discuss it further. I am very open to an entire paragraph criticizing Wikiepdia notability policies as sexist, but we need more of an argument here. - PK
Ok that's fair enough. The only way I could say this with certainty is if we found a way to calculate the strictness of the notability policy and correlate it with the gender index, but actually that's not in the scope. So maybe I was being to overreaching. -MK
There's also I realize a problem. People with more than One Gender. Like Anna Grodzka. in Wikidata the way we do it has 3 genders.
https://www.wikidata.org/wiki/Q442804#sitelinks-wikipedia
So we can't do a ratio of like women/total biographies. Because then we will add up to more than 100%. We can include her in all 3 categories, and then do a ratios like women/total genders counted. -MK
- Through it appears that there are so few of those case <100 then in our million+ dataset this is not a significant source of bias. But worth keeping in mind for the future. --Piotrus (talk) 06:17, 24 October 2014 (UTC)
Plots
editMade a nice plot today (not final) just doing it a bit myself. The share of female versus male biographies on Wikidata with dob from 1800 to 2014
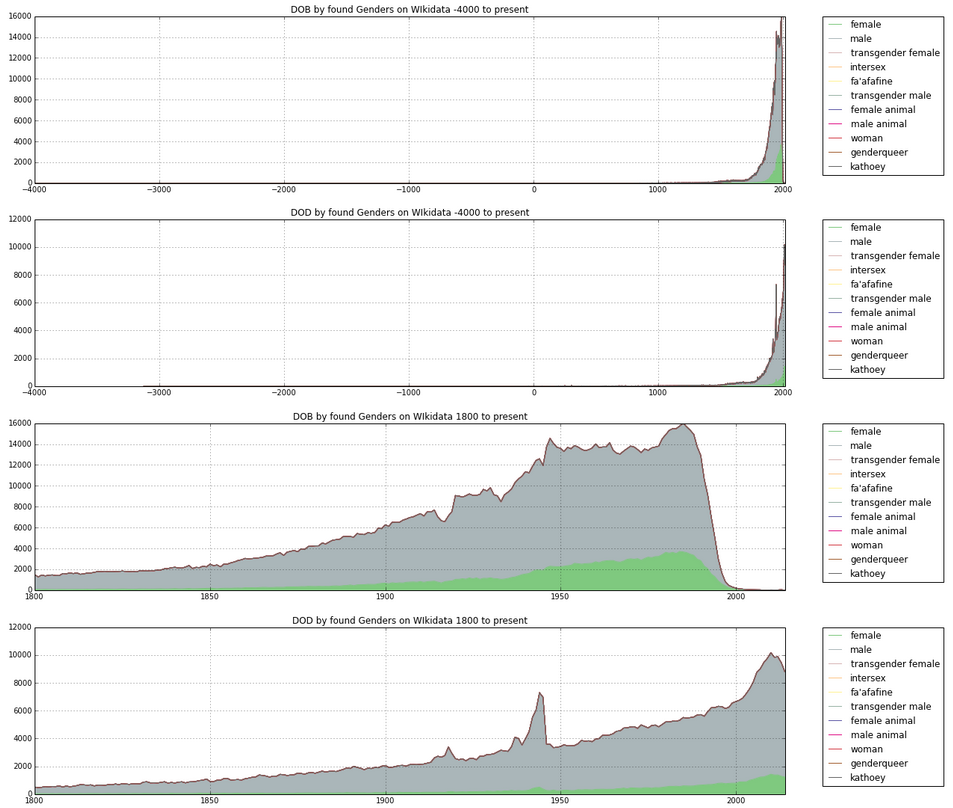
Ok, then the first graph - the blue one with the sudden spike at the end - is just the graph of all biographies by year of birth, yes? Then this is still puzzling; why the spike around - can't read it exactly - 1990-ish? It is some giagantic glut of young sportsman, musicians and such? No, wait. The Y is not the total number of biographies, it is still the percentage of... what exactly? -PK
The blue-only graph - the nonmale ratio graph - exhibits a spike at the same point that the blue/green graph exhibits a decline in total biographies. That's not a coincidence. It's that the sample size decreases a lot. For instnace in 1987 we have about 3,000 nonmales and 10,000 total biographies. Yet after the big drop in total biographies around 1987 the division is more like 50 nonmale biographies of 100 total biographies. So the ratio does indeed increase sharply, but the result is much less significant because the sample size has shrunk by an order of magnitude.
(And in the most recent years we are talking about biographies of Babies and Children, in which case they are probably only notable because of who their parents are - which means their gender is relatively unimportant! [ My hypothesis]) -MK

I dont know what the best way to do prediction is. When I do a linear regression on this data I get poor R values, but its not exactly exponential either.
What technique did you imagine using for prediction? Linear regression? -MK
I know there are ways to determine which one to use, for example IIRC plots of residuals can give indications to that - if they are u-shaped, we should use a power (x^2) regression (see http://www.statmethods.net/stats/rdiagnostics.html for more). Logistic regressions are also popular, but, as I said earlier, this is not my forte. Multiple regression requires more independent variables, and our primary one is date of birth. We can play with other variables later, but I think data of birth is good; if we get such a high R^2 it's probably a good sign. Maybe we got lucky and a simple linear regression is exactly what we need :) Through looking at the data I'd think a curve may be an even better fit. I wonder if our function isn't linear but exponential? Should definitely try a few other regressions for a better fit, and if we can figure it out, influenced by the residual analysis - also, the paper will sound better when we can dedicate a paragraph to explaining that we did it, whether it worked or not. - PK
actually, i was trying to regress the two percentages and then subtract the regressions, but if we subtract the data first we get a graph like this [[File:Dob dod totals.png|Analysis of Wikipedia Biographies in Relation to The Wikipedia Gender Inequality Indexhttps://meta.wikimedia.org/wiki/Research_talk:Wikipedia_Gender_Inequality_Index]] then using just the data from 1800 to 1986 we have quite a good linear regression This implies $y = -1.7495 + 0.001x$ with $R^2 = 0.885$ setting $y=0.5$ $\implies$ $x=2249.5$ or in the year 2250 -MK
First, I am no sure I understand the second graph. What do you mean, subtract the data? What's x and y? I assume the year is data of birth, yes? It's the x? And the y is number of biographies by gender on the first plot, and percentage of non-male bios on the second one? But is the value really reaching 0.5-0.6 near the end, i.e. 50-60%? The first graph implies this is not the case yet... The hike around 1990s is very interesting, but I want to understand the graph first before trying to speculate here.-PK
When I said subtract, I meant to make a regression of the male values, of the female values and then divide the regressions as a percentage.
But it doesn't make as much sense as calculating the percentage over time, and then regressing that. Or does it? - MK
I am still not clear on what is being analyzed here. What is the x and y axis here, and what are the formulas used to get them, if they are dependent variables? -PK
The x axis is time. The y axis is (nonmale biographies)/(total biographies).-MK
Sorry, yes, I was just excited to see the data I hadn't labeled the axes yet. X is the Year of birth. In the first plot Y is total biographies. In the second plot Y is percentage of biographies that are non-male. In the second plot the percentages are high, about .5 like you said, but I would not say the are significant as you can see the total number of bios drops sharply at about 1986.-MK
If I interpret the first data correctly, the number of notable people grows up till 1950, then stabilizes, to jump again in the 1990s and drop around 2000s, right? That itself is an interesting finding. I can understand the drop (young people are not very notable), the stabilization is also explained in a similar way. But the 1990s hike is puzzling, and so are the two small dips. I cannot read their dates exactly form the graph, but I'd expect them to correlate to world wars...? -PK
The dips are world war II. We'd have to simulataneously map world population to see where Wikipedia is outpacing anyone else.-MK
Only WWII, not WWI? With our data, aren't we mapping the world population already? Or do you mean we need to see if this dip occurs with regards to different countries/nationalities? One thing that comes to mind here is that in wars, majority of casualties are males. So those dips would make sense if we were using dates of deaths or such; as during the wars (and afterwards) more notable females than males would survive. But I'll think more about it once we clear the confusion about the graphs.
If the data is skewed due to patterns we can identify, such as young people being not notable, I think we can be quite justified in eliminating recent data (ex. 1987+) and then going with linear regression. R^2 = 0.885 is EXTREMLY high. How does it hold when we increase the range backwards, to earlier centuries? -PK
Its less good. Its not a linear regression so if we go early its a bad fit. Someone made fun of me on twitter for this https://twitter.com/drsciman/status/514614136420827137 but here are the other values -MK
You know, I am a bit confused - I thought R2 is stable for an equation. But your graph uses it as a Y axis. Shouldn't x be a date of birth, y be the percentage/number of female bios or such? Then we would have a curve, plus a linear line on the graph... -PK
This kind of a "higher-order" graph. Its the best R2 value I can get depending on the the start date of the regression. In fact now that I'm looking at it again it means that linear regression is definitely a bad choice because its so unstable. -MK
Data highlights (let me know if my analysis is off somewhere): * gender breakdown: unknown - 10.3%, male - 75.7%, female - 13.9%, other - <.0.0%, N=152 cases of other gender? * dates of birth by century: ** it does seem that our data is likely well correlated with world's population (Pearson = .983**). I've found some useful stats at https://commons.wikimedia.org/wiki/File:Population_curve.svg / https://web.archive.org/web/20061231163421/http://www.census.gov/ipc/www/worldhis.html I was unable to force SPSS to generate a multiple line graph, sigh. The unfriendliness of some software is extreme. Anyway, here's the graph:
The graph may look nicer after the data is transformed to logs. -PK
You're analysis looks right. I'ts not surprising that we are correleated with world population. It's actually a good indication, and we should put it in the paper, so show a "sanity" test for the data.
I've never used SPSS but I like R. I can help with making nice graphics when we are making camera-ready, since I've banged my head on that before. -MK

October 16th to do list based on Skype's discussion
edit1.Rerun the m/f graphing, but with nonmale/total instead
2. Find a good rolling average. 3. Do 1, and 2, but with dod 4. redo 1, 2, 3, but with October data.
Other variables Investigations. upload october reindex -MK
October indexes up
editI was thinking about justification for cutting outliers, and I couldn't think of anything good. Or, what I am saying, is that I think I might have been trying to ignore the data. I really wanted to see a nice - liner or curved - rise in the female to male ratio of bios in time. And when I didn't see it, I started blaming the data, and then cutting and massaging it until it would fit. And while the data can provide very high R^2 after this, I am not sure if this is good data anymore. I was hoping that all those outliers were bad data, but if they are not, then there may be something else going on. -PK
i agree completely. there is obviously a clear trend 1800-present. but before then 1 of 2 things is happening. (a) There isn't a clear trend in what Wikipedia Readers are taking interest in or (b) wikidata is too incomplete to reflect that trend. If its (a) That's not a bad thing. It means that there isn't a systemic bias about gender with respect to historical interest. if its (b) its a method limitation.-MK
- Max, can you elaborate a bit on what you mean here? (Also, you mean Wikipedia Readers or Editors?)? --Piotrus (talk) 07:31, 23 October 2014 (UTC)
Last week's R^2 were wrong, as I assigned the same, arbitrary value to all years that were missing female or male biograpies; it created a nice "low line" that I expected to see and that fed nicely to log-like regressions. Removing all years with a missing variable as well as those where female to male ratio is higher than late 20th century gives as this:

Not removing those outliers produces the atrocious results visible here:

The thing is, that I don't see why those outliers should be removed, other than to produce "prettier data" - and that is not a valid rationale.
Now, we certainly get very nice results for the 19th century onwards (which you already know because you reported them to me first):

Which leads us back to this question: what is making the pre-19th century data break the pattern we (or at least, I) assumed would have? Why is this pretty 1800-now line / trend falling apart in the past? There are two answers:
- our data is wrong (but we double checked and it seems not to be a data problem)
- something else
The good news is, that "something else" my be very interesting to research and discuss. And heck, even our 1800+ data is still a ~150 years improvement on the traditional gender gap indices, so it's very cool, too. -PK
Yes, one result is that the gender gap is observable in Wikipedia as far back at 1800, and has been monotonically, and exponentially improving since then. -MK
_(minus_outliers).png)
.png)
.png)
- Yep, I think that the 1800-1985 data is very sold and easy to interpret. --Piotrus (talk) 07:31, 23 October 2014 (UTC)
I liked your idea to try to smooth the data and to deal with single outlying years, but as we observed last time, it wasn't doing much. I wondered if we could make it better by going with a century smoother rather than 10 years, so I run the numbers - and no, it's not helping much. But, unless our data is borked, it is still very curious. Check this out:

I am still having trouble graphing anything nice, but this table should be quite easy to read (one error in description: should be female to male/all). I was going to attach the file, but apparently the @%#% Libre Office didn't warn me than saving to sheets in csv format would delete one of them so I lost half an hour of work (there are times I hate open source...). -PK
I can make a pretty chart out of this data, and it's not too much work for me to recreate it either. (Quite easy in python-Pandas). -MK

- Excellent, let's add this to our to-do list. --Piotrus (talk) 07:31, 23 October 2014 (UTC)
Anyway, the ratio seems to fluctuate rather than increase in time, except for the last few centuries. It increases from the 12% of BCE era to almost 20% in the first few centuries CE, given the Ancient history a ratio of about 16%. It seems to drop somewhat closer to 10% around early Middle Ages (a term that however is not applicable to world's history), and raises again in the last few centuries, giving the Postclassical Era a 15% ratio. And then the weirdest ting happens - after a spike of 20% in the 13th century we see a collapse of the ratio down to almost 5%, only to recover since, with our nice graph showing a steady rise; 20th century shows an improvement of few % by decade, possibly accelerating.
Through it's not linear, one thing that happens around the 15th-19th century ratio plummet is that the number of biographies increases rapidly, and the increase in women's biographies is not keeping pace with male biographies. For example, the number of female biographies for 14th and 15th centuries is roughly stable, but male increase by 25%. A century later, female biographies increase by 20%, but male, by 100%.
One way to interpret this would be to say that opportunities for males to be recorded in history have drastically increased around that time, yet for women, they didn't (at least, not by much). Will be interesting when we try to compare this by region, but here are some ideas (I HOWEVER STRONGLY ENCOURAGE YOU TO STOP READING THIS @, WRITE DOWN YOUR IDEAS AND THEN COMPARE - SO YOU ARE NOT INFLUENCED BY MY IDEAS). -PK
ok.... here's what I wrote before reading the rest
Piotr writes:
Observed is that duing 15-19C's female bios remained steady, but male bios increased by 25%. One theory is that opportunities for men to become notable increased.
My thoughts:
The direction insinuated here is that there is a social cause that is allowing men to become more notable. This would mean that notability is a two-part function. The implication is that Gender notability is constant + variable. Constant is things like Kings and Queens, and variable is like inventors, or adventurers. This constant+variable model is moderately accurate in my mind (but I don't know if i would want to guess how important the constant is to the variable).
Although we also have to factor in world population since I would assume that absolute notable people rises with total population. Population growth was relatively flat in 15-19c.
If we had more confidence in our data, then there may be a cause why 15-19c patterns are accurate, but as for now I can't be sure this isn't just a quirk of Wikidata's represtentativeness. -MK

.
. .
OK, here are my early ideas:
- printing press means more and more information is recorded
- men are writing about men
- men who are now written about are less important than before - lesser functionaries, priests, scientists, merchants - but women written about are the same - queens, nobility.... only in the last two centuries or so when women were able to get jobs / professions and thus became famous (notable) this starts changing again,
- would be interesting to try to analyze the professions/reasons for fame of male vs female bios but it may not be a task we can reliably do. However, we could sample a hundred or so bios? -PK
On my to do list is to get the profession data. It can be done, but I have just been slacking, and it wasn't important before, but now we need it to test your theory. Oh and I finished the place of birth research which i want to show you today. -MK

- So it appears we are both pretty much in agreement about what we are seeing. Could you elaborate a bit more on "If we had more confidence in our data, then there may be a cause why 15-19c patterns are accurate, but as for now I can't be sure this isn't just a quirk of Wikidata's represtentativeness."? At this point I am relatively convinced that our data is sound and Wikidata should not have too many errors to skew the overall picture too much. --Piotrus (talk) 07:31, 23 October 2014 (UTC)
- What I meant about Wikidata's representativness, is that I hope that Wikidata is representative of the aggregate of all Wikipedia data. Since a lof of that info is coming over by bots run on single Wikipedia one at a time its possible that Wikidata isn't inline with the aggregate of Wikipedias. Anyway, I think the above thesis at least holds.
DOB and DOD ratio differences
editI think we should include as a result that the ratios DOB and DOD show different behaviour. If they were equally recorded we'd see two identitcal lines with longitutindal shift that dates of death occur about one average lifetime after birth. But it's not the case. We find two things. Maximilianklein (talk) 23:58, 7 November 2014 (UTC)
- DOD is more historically recorded.
- DOD shows a universally lower or equal femal/nonmale percentage at all points in time.
Post-email project status / to do list
editResearch project status:
- Litreview: done and written up (see draft paper in #Key_links
- Data collection: done (see githum repositories in ##Key_links
- Research Questions
- RQ1: "taking year of birth parameter, we can compare the number of Wikipedia's biographies by gender by year (decade, century, millennium). What is the pattern/trend? Can we predict when full equality will be reached?"
- Note: We are also using date of death parameter
- Seems like from ~1800 onwards there's a very nice, linear trend of closing inequality (growing proportion of female biographies). However, pre-1800 data is surprising, not only breaking this trend but suggesting that within 5-10% range of fluctuations, that ratio was steady at about 10% from ancient history till about 15th century; then decreased to about 6% before starting an upward trend since 19th century reaching about 30% now. This needs more discussion as to why this trends happened; early idea we have relate to printing press resulting in more male individuals becoming notable (written up) whereas women did not get opportunity to increase their notability until about 19th century.
- A very controversial, limited-applicability but "fun" prediction based on 1800+ data is that gender equality as defined by ratio of Wikipedia biographies will be reached around 2250
- We may be observing some interesting patterns about women's date of death not being recorded as often as males. This may be visible in newer graphs ([1]), Max?
- Seems like from ~1800 onwards there's a very nice, linear trend of closing inequality (growing proportion of female biographies). However, pre-1800 data is surprising, not only breaking this trend but suggesting that within 5-10% range of fluctuations, that ratio was steady at about 10% from ancient history till about 15th century; then decreased to about 6% before starting an upward trend since 19th century reaching about 30% now. This needs more discussion as to why this trends happened; early idea we have relate to printing press resulting in more male individuals becoming notable (written up) whereas women did not get opportunity to increase their notability until about 19th century.
- RQ2: what will be the variations by region/country/nationality/ethnicity/religion/language?
- Now being worked on; early graph is at [2]
- We can test whether there are significant regional variations in the proportion of female biographies (a Chi-Squared analysis). We need a database listing each of the 1.6 million cases, the gender of the case, and the region of the case, which we have. We could then do a cross-tabs of gender by region and calculate a chi-squared statistic. It would likely be highly significant.
- Still need to do by-language analysis.
- Update: Chi-squared analysis done; confirmed significant.

- Coding [3]; outsource coding [4] and [5] to Amazon's Mechanical Turk (two or three separate individuals; then we compare and check for errors)?
- Comment on coding this: currently we are using the nine cultures as in w:Inglehart–Welzel cultural map of the world. Those are more applicable to modern era (1500+), but I don't know how to get around that unless we aggregate our cultures even more (into fewer groups). In fact I think such aggregation may be interesting (and very easy to do; the major difficult is aggregating those few hundred country/nationality values into few big ones; aggregating 10 into 4 of 5 is piece of cake by comparison)
- Coding [3]; outsource coding [4] and [5] to Amazon's Mechanical Turk (two or three separate individuals; then we compare and check for errors)?
- RQ3: are there interesting variations in easy to calculate variables such as subject longevity and article quality?
- I think we probably have enough fun stuff not to have room for longevity...
- Other observations that are likely worthy writing about:
- gender breakdown (September dataset): unknown - 10.3%, male - 75.7%, female - 13.9%, other - <.0.0%, N=152 cases of other gender?
- In addition to the gaping gender divide stat, it's worth noting that Wikidata stats for third gender are still very much lacking (another research paper may want to revisit this in a year or two)
- the population of Wikipedia biographies seem relatively well correlated to the world's population in general (Pearson = .983**). It's worth noting, however, that the number of notable individuals in the population increases with time; this is visible in the graph (through a log one may be better).
- gender breakdown (September dataset): unknown - 10.3%, male - 75.7%, female - 13.9%, other - <.0.0%, N=152 cases of other gender?
- finish coding, max does ethnic groups, piotr does citizenships.
- Use citizenship and ethnicity and pob to make one large aggregated aggregated culture column.
- and then culture, gender, dob, analysis graph.
- fix title and islamic colouring on the culturegendob graph.
- and add total of any column.
- dob by culture but without gender to investigate the cultural history.
- will bar graphs look better?
- contact wikiwomens collaborative after doing the above.
- plot a logistics curve to gender ratio data for only 1800, justifiying there is no simple curve that satisfies the the complete data
Discussion
editOnly 237 countries?
editI am checking the coding on https://github.com/notconfusing/WIGI/blob/master/helpers/aggregation_maps/country_maps.csv ; but 237 countries - many former entities are part of those, but I wonder - no entry for Inca Empire, for example? (Ref w:List_of_former_sovereign_states) It's one case (one we can dismiss) if a country shifted from one version to another, only sligjtly different - ex. French monarchy to republic, or such; but Inca Empire doesn't really have much of a modern successor. I wonder if we should have a coding groups for pre-colonial indigenous countries or such; but why aren't they on Wikidata? Looking at https://www.wikidata.org/wiki/Q13702 as a first example that came to my mind (Montezuma, Emperor of Aztecs, is listed as having country of citizenship value Mexico - and I can already imagine a dozen historians on the verge of heart attack / flaming rant) it seems that they are grouped under modern entities occupying their territory; at the very least it's another note for limitations). PS. On the bright side, there should be relatively few biographies from those couuntries (proportionally), so any errors should again be swamped under the mass of modern bios. This will be more of an issue if we want to look at historical (pre-modern) difference by regions; we will need to consider how all those historical pre-colonial people are categorized, and what it means for our analysis. --Piotrus (talk) 09:06, 24 October 2014 (UTC)
- Indeed, classic problem. Countries are too difficult to get right and are most useful for flame-generation, see also Research:Newsletter/2014/August. At any rate I recommend to avoid hardcoding country stuff in your work, to avoid Hidalgo's pains; much better to work on Wikidata, see in particular d:Property talk:P27. --Nemo 09:16, 24 October 2014 (UTC)
- Max can tell you a bit more about the problems with the Wikidata variables; one of our solutions is to code them into cultural regions based on the w:Inglehart–Welzel_cultural_map_of_the_world, through that doesn't scale that well over history (but what does?). Any suggestions are appreciated. --Piotrus (talk) 09:34, 24 October 2014 (UTC)
- @Nemo bis and Piotrus:, what I did was find all the place of births (pobs) for every human. Then for each pob, I found if it had property:country (P27). 93% of cases did. What you see as the 237 countries listed are all the P27 claims. Maximilianklein (talk) 18:52, 27 October 2014 (UTC)
Difficult cases for
editFirst, I'll note that we don't care about recent (last few decades) shift so much as the more historically accurate description (hence, raise in atheist values is irrelevant as it is too recent to matter much for us)
I moved Lithuania from Protestant to Catholic Europe based on my knowledge of Eastern European history; few other minor and uncontroversial changes are in github's history (mainly I reclassed various -stans from Orthodox to Islamic).
Why is London on that list?
But what to do with Q801,Israel,2,orthodox? Inglehart–Welzel classifies it as South Asia, for no reason I can fathom. Map placement locates within Catholic values; through I considering that many Jews came from Russia, I wonder if the orthodox isn't the best. I don't think there's a way to classify it on that map and make everyone happy... --Piotrus (talk) 09:34, 24 October 2014 (UTC)
Amazon Turk Results
edit@Piotrus:, Got the Amazon turk results for coding the ethnicities and citizenship into the 9 world cultures. We need to still do some help coding, maybe we can split up about the 500 remaining cases:
results_citizenships.csv
229 disgareements
0.3357771261 as a percentage
results_ethnic_groups.csv
284 disgareements
0.387978142077 as a percentage
By the way the instructions I gave was to use the Historical coding. So for "British Raj" Use English speaking, not India/ South East Asia.
Here are the files on github https://github.com/notconfusing/WIGI/tree/master/helpers/aggregation_maps/for%20mechanical%20turk the .disagreement.csv files. Maximilianklein (talk)
- Should I started editing the pages directly?
- Regarding the historical coding, I wonder if we should try to create some sort of historical version of the Inglehart's clusters; after all things like "Protestant Europe" become irrelevant for the times before Protestant revolution. At the same time, this could be easily coded; for 500-1500 I'd see English-speaking, Europe and Christianity merged into Europe. But as I noted with the Montezuma example, we may want to have some form of pre-colonial Americas category.
- Now, at the categories, many erros are easily fixed - I can take an hour or two and probably do both lists, at least 75% cases. Ethnic groups is pretty simple error-fixing (outside some cases where there's no good answer, ex. Austro-Hungary was both Catholic and Protestant europe). For citizenships, I'd go with modern, so Spanish American -> Latin America; Swedish American -> English speaking (because this is where most of them would live). Still have some outliers; I think we may want to create a new cluster/group for Jews. We may need "other" trash category for stuff like Mixed race.
- On that note, a thought about File:Place_of_birth_analysis.png - we should probably redo it with only post-1500 biographies.
- Now, isn't it possible that a person may have multiple ethnicities/citizenship? What to do then? Assign that person to multiple groups, I guess (through this will result in the N of subjects going up)? We could try to test two datasets, one when people with more than one categorization are excluded, and one where they are includied in numerous groups. To be honest, I don't think either will differ much.
- The coding question is difficult because I don't think there is one way to do it that is more "denfensible" than any other. In every process where we try to organize 700 ethnicities into 9 groups (or any amount of groups less than 700) we will be losing information. The purpose of doing this aggregation is to get more easily visualized and understood information. I think the way the pob-data was graphed showed that usefulness, we are only making large generalizations, but they still might be instructive. So either I think we should drop the idea of aggregating if you feel we can't do it well, since the result will be to destroyed by our poor methodology; or I would have you choose the methodology that would stand up best to the sociology community if you think we do get something useful out of make the aggregations. I leave it up to you. Maximilianklein (talk) 19:05, 31 October 2014 (UTC)
- A thought on some specific "to do" tests when we are done coding. First, we may want to see if there are any significant differences in the non-male biographies % and trends. I.e., will we see the ~15th century dip everywhere, or will it vary in time? Ditto for the 19th-century rise. Second, how are the prediction lines for gender equality looking by cluster? Can we show (as one would expect) that the English-looking cluster achieves the parity faster than Islamic, for example? --Piotrus (talk) 06:46, 31 October 2014 (UTC)
- That's a curious, but advanced idea. You are talking about analysing three variables at the same time: place of birth, date of birth, and gender. Let me check about how many records have all three of these data... its 546,132. So its not that significant, but can be done. I'll put it on the to do list. Maximilianklein (talk) 19:05, 31 October 2014 (UTC)
- Max, another to check numbers basic descriptive numbers: for our latest dataset, are the following sentences (numbers) correct?
- "As of October 2014, out of approximately human (Q5) (2,561,999 links) biographies on English Wikipedia's only about 14% (N=359,906) are female"
- Gender distribution: data missing - 10.3%, male - 75.7%, female - 13.9%, other - <.0.0%
- 1,359,151 (excluding 1985) have a recorded date of birth (so about 54%)
- for period 1500-1985, we have a total of 1,340,753 biographies with recorded date of birth; hence 98.5% of our data concerns a period of modern history (1500-1985) [this, btw, is why I think we don't have to worry about the pre-modern history biographies that much, the 1.5% that they seem to constitute is unlikely to skew the data too much)... Still, as many of those missing dob biographies are from a prior period of history, should we simply exclude them? --Piotrus (talk) 08:42, 31 October 2014 (UTC)
- I looked at the relation between missing date of birth and gender. Good news is the populations seem not be statistically different when it comes to gender distribution; both show about the same ratio of females to males. Which means that we can probably safely use the 1 million or so entries with date of birth missing. The only difference is in the fact that about 90% of the entries with gender mission also have date of birth missing - probably bad, or very underdeveloped entries. This is primarily of relevance to our defense of whether we can use the nine-cluster cultural map for all of our data. As I've noted above, 98.5% of data with recorded dob falls into 1500+ range, so it's totally fine for us to use it for all dob data. But I wonder if someone could try to argue that most of our missing data falls into the pre-1500 era. I don't think that's the case, and the fact that the gender ratio in the dob and dob-missing groups seem to be nearly identical supports my conclusion, but I wonder if we could try to improve our data somehow? En wiki uses categories for decade or century of birth; I wonder if we could extract it to provide a secondary value? Or is it not worth our effort? Again, a potential solution would be to report statistics (graphs) for a) set of entries with dob data only and b) for all. --Piotrus (talk) 09:23, 31 October 2014 (UTC)
- I don't want to rely on English Wikipedia for any supplementary data, since I think it could introduce more bias, maybe we will have to separate into dob-having and no-dob records, as a supplementary test, to dispell this one critique. Maximilianklein (talk) 19:26, 31 October 2014 (UTC)
Update: I've finished resolving no_agreements for non-historical countries in https://github.com/notconfusing/WIGI/blob/master/helpers/aggregation_maps/for%20mechanical%20turk/results_ethnic_groups.csv.disagreements.csv. Notes: I was following the IW map for some not-clear cut cases, so Ireland was assigned to English-speaking over Catholic, and north-African Islamic states were coded as Islamic (may need to check the agreement values for those). 2) I have recoded historical entries into new proposed categories: Jewish, pre-modern European; pre-modern Middle East and pre-modern Middle East Americas. I don't think we need to recode the data into Oceania (I used South Asia for it), through if you think it's worthwhile, I won't oppose. 3) I am not impressed by the coders quality ("Argentine,Catholic European,English-speaking" -> wrong, wrong, sigh). Given "Niger,Africa,Catholic European,no_agreement" and "South Africa,Africa,Latin America,no_agreement" I am tempted to dispute coder two claim for compensation; if s/he cannot be bothered to code South Africa correctly into Africa, they don't seem to be taking it seriously. That said, "Canada,Catholic European,English-speaking" is also not saying much about coder 1. Perhaps we could calculate the ratio of errors; it's not a very difficult task and yet it seems that both coders were about 50% times wrong or so. The inability of either coder to flag an obviously erroneus entry ("sculptor,Catholic European,English-speaking") as such is another indicator of a problem with the data they returned. It is very clear than in most cases (never?) they bothered with a simple look-up of entity on Wikipedia. 4) Somehow female animal made it into some of the data, probably a reason for "Icelandic cattle" entry... 5) remaining no agreements are likely errors to be pointed out / fixed on Wikidata. --Piotrus (talk) 08:41, 5 November 2014 (UTC)
Pob Dob and Gen
editI can't seem to find it in the thread now, but you asked for this analysis @Piotrus:. To look at the Data by all three variables at once: Pob, Dob, and gender. Here's what I found. I have some theories, but I think you should take a look before I write it. From earlier:

later timeframe:
 Maximilianklein (talk) 02:35, 7 November 2014 (UTC)
Maximilianklein (talk) 02:35, 7 November 2014 (UTC)
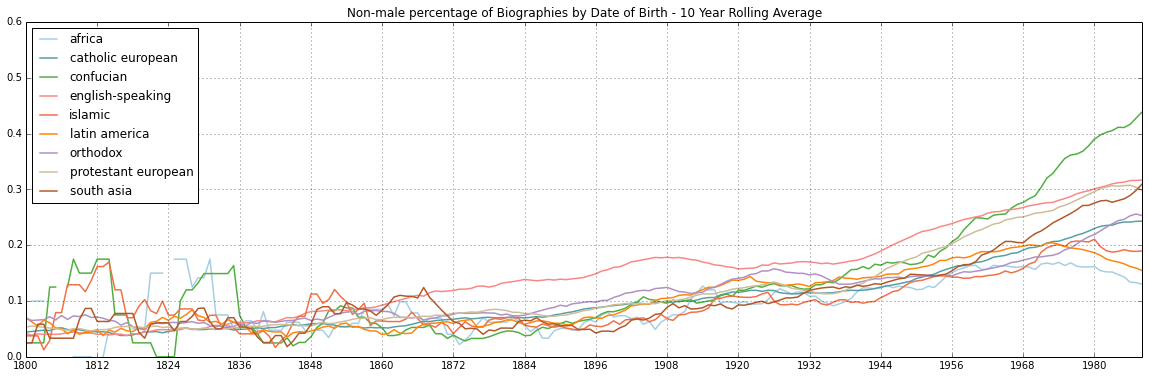
- I've been thinking about them since I saw them on Friday. Very interesting. Which data set were you using? [6] or [7]? Here are my thoughts (as usual, I encourage you to jot yours down now so you don't get contaminated by mine first):
- can you re-do the maps with Islamic assigned a different color? Their yellow becomes nearly invisible on the map; they do appear to be near the bottom pool in the modern era, as expected, but
I cannot comment on when they appear early on, as I simply cannot make them out on the graph. They should appear early, but do they?Update: squinting at my laptop screen from a different angle did reveal that line, it appear early on, I think around -300BC or so, which roughly ties in with the historical importance of that region. Should in fact appear even earlier, around the Greek rise - which would lend credence to the Western bias (but here is also the issue of Greek history being, I think, better preserved than Babylonian or Persian or such). - on that note, a new graph that disregards gender, just plots the percentage of entries from a given cluster in time, may be fun to look at and comment on regarding Wikipedia's bias towards Western sources and such (ex. will we have more entries on European than Islamic or Confucian topics in the Middle Ages, when Europe was a backward dump compared to the more developed ME/Conf regions?)
- We clearly see the bias towards Western recorded history, as the Catholic Europe dominates the old entries.
- I am a bit puzzled by the Orthodox spike preceeding the Catholic Europe one. My best explanation is that this represents the Greeks, as they were coded as Orthodox. If so, this tends to support my idea of recoding the data of some places into pre-modern entries, but it's not a biggie - we can draw the same conclusions otherwise, too. But it would make for a nicer graph, I think.
- The rise of Protestant European countries happens a bit earlier than it should, around year 1000. This again reflect the fact that we were coding those cultural countries without dividing their history, for the most part, into pre-modern and modern, but it is also easily explained: non-English Protestant countries such as Germany didn't get important around roughly that time. So this is just a confirmation of the European bias. The re-appearance of the Orthdox line around 1500 is probably related to the rise of Russia, which again wasn't that important until around that time.
- the English-speaking line appears over Catholic Europe around 1200s-1300s. I am in fact not very well versed in the medieval British history, but I guess that would be the time it became important, too...? I am a bit iffy on that.
- the emergence of other lines in the 1600s/1700s suggests a strong Western sources bias. African, South Asian and Confucian emerge around that time, and particularly the Confucian (China) should have appeared earlier on. It is in fact this anti-Chinese bias that puzzles me significantly here; would love to see the non-gender graph for this. (Yes, I see a few confucian color orange dots, but just dots - either we have to little data, or the Confucian early history was very male-dominated, much more so than any other).
- now, the above was about the non-gender cultural (Western) bias in our data. Gender wise, my thoughts are as follows
- The non-male (but realistically, female) to male ratio seems to spike twice. First, around 300-400 CE, reaching about 30%. Then it tends to dip to about 10-20% around 1000 CE and rises up once again for another spike around 1400-1500 CE, in order to drop once again to about 10-15% (we could use one aggregated line here as well to get more specific numbers). Finally, it rises steadily since then.
- Wheres we have discussed the 1400-1500 CE decline and subsequent rise, I am not sure how to explain the preceding trends. The orthodox line seems stable. Islamic line could be explained by the rise of Islam, perhaps, further limiting the opportunities for women. But how to explain the slight (pre-Islamic) and Catholic peak, I am not sure. It suggests that the opportunities for women to became notable were increasing until about 500 CE, then dropped. Regarding Europe, we are looking at the fall of Roman Empire and the rise of Christianity. The two very early thoughts I have are about Roman Empire being more open towards women's notability (carrer opportunities/recording women dates of births) than the Christian states, and that the "Christianity/Islam" (can't speak about religions of the book without a separate Jewish set to analyze) would be less so than the "pagan" religions they preceded. But I'd have to go do some lit review to see if anyone has anything to support this. Perhaps we could ask on the gender forums? I can ask on the WikiProjects/Facebook wiki-gender groups I am familiar with, and I think you may be familiar with some listervs?
- Finally, by cultural group analysis. Catholic Europe ratio seems to be higher than than the stable Orthodox and more similar but lower Islamic ones. How to explain Orthodox (Greece, then Russia) stability, I am not sure. Would seem that whatever opportunities appeared in Europe (Roman Empire?) didn't extend to Greece/Russia, and were less pronounced in the pre-Islamic/Islamic world. The Protestant cluster enters with a higher ation than the Catholic ones, suggesting that early on those countries might have been more open towards women, but they equalize after a century or so. English speaking (UK, at that point, really) cluster also enters with a higher ratio, that takes a century or two to equalize with he other European ones.
- I wonder if those early spikes - also visible in African and South Asian, but not Confucian data - tell us something about early recorded history of most regions? Something like - early on, most individuals recorded are aristocracy/royalty, and then male get more opportunities and women's ratio drops? The Confucian data is the odd one here, appearing way too late and without a spike. (Max pointed out that the same spikes happen early on to Catholic/Islamic... perhaps it's the same for all data)
- The laast two centuries show a lot of zig-zaging for lines with presumably fewer data points (non-Western, really). Perhapps a longer rolling average could help smooth them out... but what seems clear is that there are no significant differences between region until the last few decades. The English speaking (UK, USA, Australia, Canada, New Zeland) seem to place themselves a bit above the rest, starting from the 1870s, which I think is likely a result of the early success of the women's right movement in those territories. I am not an expert here, but I do recall that most of early victories for women's voting rights, for example, were US and the British Commonwealth (with the UK following late after WWI). Around the WWI/WWI period we see the English line overcome by Protestant (only two switch again around 1970s or so), with Catholic Europe always a bit under these two. What is surpsising, however, is that - counter-intuitivelyu to me, at least - Islamic line is not significantly lower than the Catholic one; in fact the Catholic, Islamic, Orthdox and Latin American one are pretty similar. The outliers, in the last few decades, are Africa, the only line showing a declining trend, and the stellar sie of Confucian and South Asian lines, bypassing Western ones. By 1985, where our date cuts off, we end up woth three groups: Asian at 40%; Western/LA/Islamic at 20-30% range, and Africa plummetting towards 10%. That's quite a major change from the previous relatively steady and slow rise in which all of those lines were resembling one another (around 1900, all but English were at 10% range - English at about 15%; around 1950% all fit within the roughly 11-22% range....).
- That's it for me. Love the data, it's super-interesting. Your thoughts? --Piotrus (talk) 02:03, 12 November 2014 (UTC)
- As for Europe the interpretation seems rather obvious: in the periods when the Roman pope was strong, women disappear: you have the first peak before the Holy Empire is created and then the second peak in the period of communes; after Augsburg and Trent (~1550) you have the fall. The simultaneous peak, around 1200, of what you absurdly called catholic and protestant Europe may just be the influence of Italian republics and the Hansa, or something like that; England entered the business of serious commerce at least one century later and the higher peak can just be explained by the overrepresentation of English-speaking people on en.wiki. I'm just speculating, but it's easy to come up with explanations; harder to prove them.
- What's weird is that Renaissance and WWI don't have a greater effect. Especially WWI was the first event in western history causing the actual masses of women to get out of their homes, one should see something going on for the women born at the end of 19th century. --Nemo 13:56, 14 November 2014 (UTC)
- Given that we are operating with a 10-year average of date of birth variable, some delays are to be expected. I am not sure if we can say that WWI had no effect; we the turn of 19th to 20th century is the beginning of the steady trend in the rise of f/m percentage; i.e. more and more women slowly became notable. It is gradual, as most of those women-workers around WWI (and elsewhere) were, well, just low-skilled, low-payed labor, not a material for being written about by encyclopedia regardless or age or gender. --Piotrus (talk) 10:13, 19 November 2014 (UTC)
- @Nemo bis: you bring up some excellent points, our codings by religion do not work well for the pre-modern history. We mean, the part os europe that are now primarily x or y religion if you had to choose. So @Piotrus:we either need to change these codings by date, or be more careful about what we mean (i.e. change the labels).
- Given that we are operating with a 10-year average of date of birth variable, some delays are to be expected. I am not sure if we can say that WWI had no effect; we the turn of 19th to 20th century is the beginning of the steady trend in the rise of f/m percentage; i.e. more and more women slowly became notable. It is gradual, as most of those women-workers around WWI (and elsewhere) were, well, just low-skilled, low-payed labor, not a material for being written about by encyclopedia regardless or age or gender. --Piotrus (talk) 10:13, 19 November 2014 (UTC)
Culture by date
edit- Two more graphs as you requested them.


Seems like WWII had a really big impact. Maximilianklein (talk) 00:18, 14 November 2014 (UTC)
- Yes, and so did WWI. But what happened to Protestant Europe? It doesn't recover unlike Catholic/English groups. It's a bit hard to tell based on the average, but it seems that it's the WWII spike which we are looking at. I am at a loss how to explain it; Holocaust cannot be the entire story... Also, why isn't the confucian group showing any spikes? China and Japan were part of WWII and their losses weren't tiny. Could you also generate those graphs for older (pre-1800) data? That said, we are looking at dob , not dod here; a version focused on dod may be more enlightening. Finally, to make the graphs more readable without turning them into logarythmic counter-intuitive mess, how about we map each number as a percentage of total dob (or dob) for that year? --Piotrus (talk) 08:53, 14 November 2014 (UTC)
- I find the division in "catholic Europe" and "protestant Europe" very disturbing. I thought the cuius regio eius religio had ended quite a while ago. --Nemo 13:40, 14 November 2014 (UTC)
- Do you mean the division that happens around 1930s? (Keep in mind that graph doesn't talk about gender, just the number of total biographies by date of birth). It is very weird; it suggests that from 1930s the number of notable people born in Protestant European countries suddenly nose-dived. Max, can we generate a version of the graph with Germans/Austrians coded as a separate group, or merged with Catholic, to see if it is primarily Germany? A list of Protestant countries would also be helpful, which one is it? If you point me to it, I'll compile the list and my thoughts on it. Trying to describe what we are seeing I would say that the number of notable people born in Protestant and Catholic Europe (and also Orthodox countries, if a bit less affected by this) took a significant dip around WWI. Now, here's my theory: war casualties and refusal to have children at all (so to avoid them being born into a war-torn country). Children were killed, regardless of gender (but male children probably more likely, as they would be enlisted earlier, selected for "kill instead of rape" atrocities, etc.). This rebounds with post-war baby boom, only to be affected twice. Looking at the graph above, I spotted another weird element - why isn't the English-speaking line taking a dip together with the other European ones around WWI? How about this: look at the death as % of the total population at w:World_War_I_casualties and w:World_War_II_casualties. US was never affected by civilian deaths/pregancy avoidance due to war conditions (through I am guessing the latter; haven't consulted the literature on that). UK wasn't in WWI, but was more in WWII (through Wiki pages linked have numbers that don't make sense here... likely an error of some kind; I've raised this at w:Talk:World_War_II_casualties#UK_civilian_deaths_-_higher_in_WWI_than_in_WWII.3F). I would still expect the English-speaking dip to be lower than it was, as it is it mirrors the Catholic Europe, and I can't think of why it should. Granted, Spain, Portugal, and Switzerland were not involved, but... Also, the WWII dip happens in the 1930s, but the WWI, around WWI. So the WWII dip is a decade to early. Max, could you generate it with no moving average, or maybe a 2-year one? There's something strange here I not understanding yet, and we should make sure this is not due to some error in data. Maybe worth scanning the "coders-agreed" data, just to double check if they haven't messed up with a major country or such (such as misclassifying US...). --Piotrus (talk) 10:13, 19 November 2014 (UTC)
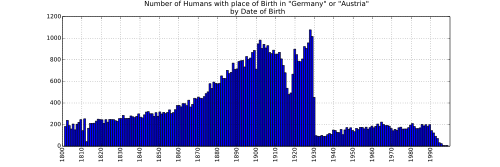
- @Piotrus: Here is that data you requested. It really seems like Wikidata is acting very Germa-phobic immediately because of WWII. Maybe this is a big finding - hey there is a very big cultural implication here. Also it's not strange that the drop it occurs before the War, because it's when the war-time people were being born that we're looking at.
- @Maximilianklein: This is very weird. Which file was used to generate this? I think there's a problem with the data here (if I am wrong, then we have a very interesting finding - but first we have to try to prove the "data is wrong" hypothesis wrong). The best way around out is to compare a list of Germans and Austrians from let's say 1928 and 1933 and see who is missing. --Piotrus (talk) 09:04, 28 November 2014 (UTC)
- I find the division in "catholic Europe" and "protestant Europe" very disturbing. I thought the cuius regio eius religio had ended quite a while ago. --Nemo 13:40, 14 November 2014 (UTC)

Piotrus state of the project and to-do as of 21 Nov 2014
editLet's recapitulate. We want to provide data files, graphs and analysis of gender inequality going much further than variables available in major modern gender gap indexes (which rely on modern economic/political/social stats/surveys and mostly begin around Cold War era). We are using a variable of ratio of female to male on Wikipedia(s/data/etc.).
- We have successfully collected data from Wikipedia and coded it by nine major cultural groups from w:Inglehart–Welzel cultural map of the world.
- Our data has some interesting results (not all unexpected, but nice graphs either) way for general demographics, too
- File:Dob dod totals.png and File:Wikipedia_biographies_correlated_with_population_growth.png show that Wikipedia notable bio's population roughly matches the growth of the human population. The spikes in dob/dod there are fitting with WWI/WWII, but are still very interesting. Related discussion is at #Plots
- File:Rolling_average_analysis.png allowed us to further discuss the trend of the f/m ratio changing over time (I won't repeat the conclusion). There's also the table at File:Gender_ratio_by_era.png. They are discussed at #October_indexes_up (second part).
- File:Culture_dob_earlier.png and File:Culture_dob_later.png look at the nine Inglehart–Welzel cultural clusters, but still without the gender. The analysis of this is discussed above at #Culture_by_date
- We are is using the place of birth parameter to assign bios to the cultural clusters.
- To do: Max, if the images are using place of birth, can we generate those exact images for ethnicity and citizenship data? Or am I getting confused about which variables we use to assign biographies to cultural cluster?
- Answer: "Culture" is determined by all three of the place of birth, ethnicy, and citizenship variables. I do a look up on each one and then use a prefence hierarchy in the order just listed.
- I see. Max, could you expand on this a bit, in a form that we could copy into the final paper? --Piotrus (talk) 07:08, 11 December 2014 (UTC)
- Answer: "Culture" is determined by all three of the place of birth, ethnicy, and citizenship variables. I do a look up on each one and then use a prefence hierarchy in the order just listed.
- To do: Max, if the images are using place of birth, can we generate those exact images for ethnicity and citizenship data? Or am I getting confused about which variables we use to assign biographies to cultural cluster?
- Starting with File:Place of birth analysis.png, we started to look at the gender. This file is not concerned with the time axis, just gender and the cultural cluster. They are also discussed at #October_indexes_up.
- [[8]] and
 take the proceeding data and plot it on time line. The related discussion is at #Pob_Dob_and_Gen
take the proceeding data and plot it on time line. The related discussion is at #Pob_Dob_and_Gen
To do:
- Something is not right with the data for File:Germans_and_austrian.svg. This is just too weird. We need to investigate this further.
- Ditto for confucian and s-a asia line at File:Culture_pob_dob_later.png. Here we can sample a bunch of women from that period by cluster and see what, if anything, makes them different. If we could regenrate this graph using English Wikipedia only, I wonder if we would see a different picture? Is there something about different notability rules? This we could find without a graph, just looking at the wikidata entries, see if they have only native, or international entries?
- We do need data on how different Wikipedias compare to one another, i.e. what are the different gender ratios of biographies on specific Wikiepdias? Ex. is there a difference between rations of English, German, Chinese, and Arabic Wikipedias, for example? --Piotrus (talk) 08:22, 21 November 2014 (UTC)
- Update: early results at [9]
- With respect this is EXACTLY what you can find in Wikidata.. GerardM (talk) 07:22, 24 November 2014 (UTC)
- @GerardM: Could you clarify what you mean as "what", and "how"? I.e. I don't understand what, from my post, can be found on Wikidata, or how. Do you mean that those graphs are there, and this study has been already done? --Piotrus (talk) 09:56, 26 November 2014 (UTC)
- I mean that those numbers are queriable from WDQ and have been for quite some time. It is just a matter of regularly reporting and you have your graphs. I do not know what data you are using but it seems static and divorced from the real world. GerardM (talk) 08:05, 2 December 2014 (UTC)
- @GerardM: Could you clarify what you mean as "what", and "how"? I.e. I don't understand what, from my post, can be found on Wikidata, or how. Do you mean that those graphs are there, and this study has been already done? --Piotrus (talk) 09:56, 26 November 2014 (UTC)
- With respect this is EXACTLY what you can find in Wikidata.. GerardM (talk) 07:22, 24 November 2014 (UTC)
An idea for a follow up study
editWe could analyze whether the gender of the Wikiepdian (article creator) affects the gender of a bio they create. This would have to be a smaller sample, however, as the editor's gender is not machine harvestable. We could however chose a sample of editors, preferably going by the list of most prolific ones (or just a random sample of, let's say, a 1000), code their gender (more than half would be unknown, based on my experiences), and see if the results are interesting. But this is something for the future (unless we get torn apart by the reviewers on not having this...). --Piotrus (talk) 01:29, 12 November 2014 (UTC)
Wikidata
editHoi, I have blogged (again) about gender diversity. For me it is quite simple. ALL Wikipedia articles are linked to Wikidata. Increasingly we know about the gender of a human on Wikidata. Having nice progression bars based on the Wikidata will stimulate people to add more gender information on Wikidata and consequently we will know more precise the ratios in all the diverse Wikipedias. It makes a lot of work unnecessary and it will stimulate work on the real issues. Thanks, GerardM (talk) 08:59, 23 November 2014 (UTC)
- +1. Indeed, studies such as this one do a lot of good to Wikidata (and hence all the Wikimedia projects). --Nemo 09:06, 23 November 2014 (UTC)
Re: The Germanic Shift
editOn [10], I'm not sure why you say Wikidata has "moved" in a certain direction: did the percentages vary significantly across different dumps? As for things to check, please check if the percentages vary a lot when including only the statements (not) imported from Wikipedias: quite often, in categories and templates, we just call one "German" to avoid going into historical details. Of course, after WWII Germany has been split again, which causes some confusion.
Once again, let me complain about this religion-centric division of the world: it really makes no sense to call an East Germany citizen a "protestant Europe" member, let alone Bavaria. Just call it Mitteleuropa as intellectuals normally do. If you really need some "nationalist" regional subdivision, use language instead, which has always been the only unifying factor of the Germans since the Middle Ages and before; at least you'll have Über die Verschiedenheit des menschlichen Sprachbaus und ihren Einfluss auf die geistige Entwicklung des Menschengeschlechts on your side. --Nemo 08:47, 15 December 2014 (UTC)

We look at every site link of every human item in wikidata and the associated gender. then we aggregate by language family. - @Nemo bis: thanks for the feedback, I think I might move the labels to less religion based principles, because as you pointed out we are really aggregating on region and language. @Piotrus: what do you think? P.s. The previous pictures have been updated with the multi-modal culture assignment based on citizenship on and ethnic group, as you wanted before. Also (and nemo, the labels aren't changed here). But I did an aggregation by language links, and this is what came out.

Maybe you can think of a better aggregation scheme?
- @Nemo bis: Names are based on w:Inglehart–Welzel_cultural_map_of_the_world, an established grouping of cultural entities in the world. Whereas I am know aware of any major studies using world-wide groupings including the term Mitteleuropa.
- Graphs look good! --Piotrus (talk) 11:45, 26 December 2014 (UTC)
Investigating Confucian mystery
editAs our graph shows, Confucian bios seem to have an over-representation of female biographies. For now, we are investigating word frequency counts using the data at https://github.com/notconfusing/WIGI/tree/master/helpers/inspection/readable . Currently we have Japanese, Chinese, ur? and tl? datasets. I assume we will have some western for comparison. I am using [11] for word counts. Max, if you can, can you create those files divided by gender? I'd like to be able to compare by gender word frequencies for major Confucian groups (what are they? Can you list them?) and Western (a few will be enough, English-speaking, German, French, Russian would do, for example). --Piotrus (talk) 12:07, 26 December 2014 (UTC)
Update.
Japanese frequencies: Seem to be doninated by soccer and baseball players. (sportsman in general) 5550 professional (presumably goes with player...), 4965 plays, 4765 career, 4180 club, 3609 footballer, 3355 league, 3264 player, 2842 football, 1181 champion, 1105 midfielder, 1007 pitcher; other sports - 913 skater, 764 basketball, 675 olympics, 540 medal, 465 volleyball, 459 wrestler, 390 tennis, 367 winger, 321 martial, 298 cyclist, 297 boxer, 287 outfielder, 277 racer, 267 goalkeeper, 204 athlete, 165 driver, 161 soccer, 160 rugby, 149 swimmer, 110 kickboxer, 104 jumper). First break from this is 1685 actress (note the feminine word; actor is only at 1027 actor), other professions: 1282 singer, 728 model, 531 film, 483 television, 387 songwriter, 368 idol, 233 music, 156 fashion, 149 pornographic, 149 musician, 143 producer. 685 medalist, 683 competed, 682 performance, 571 debut, 413 dancer, can go to both sport and entertainment. I stopped listing professions by the time I got to about 100 frequency; note 90 director, 9 businesswoman, 2 businessman, 9 owner, 12 president, 3 researcher, 1 scientist.
I have several thoughts on that:
- this data is for the 1980 births (or 1980-1985, or 1980+?), thus skewed towards professions young people can become famous early on
- It's 1980+.
- this data is still fine for comparative purposes with other cultures / countries.
- confucian line starts diverging from the others around 1950s-1960s. A comparison with its own set from let's say 1940s may be able to shed some light, too. In other words, it would be interesting to look at those professions for Japanese/Chinese/etc. from few decades early.
- I really think we need to divide this data by gender to get a better understanding, Max, so for now I'll stop with this breakdown. I'll resume (or you can) when we have .csv files that, ideally, for each of the following nationalities (let's say Chinese, Japanese, Korean, French, Russian, American/English) come in four sets: male, female / people born 1930-1940, people born 1975-1985.
- I can do the word frequencies, unless you can whip a script that would give us all of that qucikly. With a .csv file like you made it's not too much trouble, it's really 5-10m for me to produce the above numbers, so if the script would take more, the .csv are fine.
- Oh, and 109 prince, 58 princess... inequality present even here? And more so than with 67 king 50 queen?
- I am close to scripting this. One of the problems is that I try and get the english page, but if it doesn't exist i get the foreign page. so we have to do searches with the foreign text as well, so you have to look for the japanese word for actress. I actually do this, I am just waiting for the script to finish. Maximilianklein (talk)
On a sidenote, 397 female to 111 male / 171 girl to 75 boy is an interesting commentary on the fact that describing something as female is also biased (men is default and usually omitted). --Piotrus (talk) 12:33, 26 December 2014 (UTC)
- @Piotrus and Nemo bis: So i got the data for english and german (actually 10% random samples, because the sets are much bigger). So I allow either the english word, or the foreign word to appear from these dictionaries
actress_dict = {'jawiki': u'俳優', 'zhwiki': u'演員', 'tlwiki':u'artista', 'urwiki': u'اردو', 'dewiki': 'schauspieler' , 'enwiki' :'actress'}player_dict = {'jawiki': u'選手', 'zhwiki': u'運動員', 'tlwiki':u'player', 'urwiki': u'کھلاڑ', 'dewiki': 'spieler' , 'enwiki' :'player'}
- These are the results of the percentage of biographies that have these words in the first 200 characters, so there is something to the theory that those wikis contain a bias to celebrities.
| player | actress | either | |
|---|---|---|---|
| enwiki | 0.223995 | 0.042483 | 0.266478 |
| jawiki | 0.198402 | 0.090304 | 0.288705 |
| dewiki | 0.287200 | 0.075000 | 0.362200 |
| zhwiki | 0.251717 | 0.121909 | 0.373626 |
| tlwiki | 0.068075 | 0.419601 | 0.487676 |
| urwiki | 0.016148 | 0.741638 | 0.757785 |
celebrity_dict = {'jawiki': u'俳優', u'選手', '歌手', 'ミュージシャン', 'モデル', 'アイドル', 'zhwiki': u'演員', u'運動員', '歌手', '音乐家', '模特兒', '偶像', 'tlwiki':u'artista', 'aktor', u'player', 'mang-aawit'. 'musikero. 'modelo', 'idolo', 'urwiki': u'اردو', u'کھلاڑ', 'گلوکار', 'موسیقار', 'ماڈل', 'بت, 'dewiki': 'schauspieler' , 'spieler', 'Musiker', 'Sänger', 'Modell', 'Idol', 'enwiki' :'actor', 'actress', 'player', 'singer', 'musician', 'model', 'idol', 'kowiki' : '배우', '선수', '가수', '음악가', '모델', '우상'}
- @Piotrus: here is the graph we discussed

- @Piotrus: here is the graph we discussed

![[1]](https://github.com/notconfusing/WIGI/blob/master/figs/rolling_average_analysis.png){kind=link}
![[2]](https://github.com/notconfusing/WIGI/blob/master/figs/pob_agg.png){kind=link}
{kind=link}
![[8]](https://meta.wikimedia.org/wiki/File:Culture_pob_dob_earlier.png){kind=link}
World Economic Forum Comparison
editI did a comparison with the world economic forum, gender gap report and between the data gender data we could convert place of birth to be into countries. Remember of 2.1 million items we get about 600,000 who have a place of birth that can be linked to a country within one wikidata hop. And the way we are ranking them is by the number of female (and nonbinary genders) to male.
This is the list, but the short story is that a Spearman rank corellation is only 0.1, and not very significant rho = 0.25. So a ranking based on historically recorded births is not closely related to the way the world economic forum ranks the gender gap by country. Maximilianklein (talk) 21:48, 27 December 2014 (UTC)
| Economy | Rank | Rank_wikidata | diff | abs_diff | |
|---|---|---|---|---|---|
| 0 | Iceland | 1 | 73 | -72 | 72 |
| 1 | Finland | 2 | 49 | -47 | 47 |
| 2 | Norway | 3 | 58 | -55 | 55 |
| 3 | Sweden | 4 | 32 | -28 | 28 |
| 4 | Denmark | 5 | 59 | -54 | 54 |
| 5 | Nicaragua | 6 | 25 | -19 | 19 |
| 6 | Rwanda | 7 | 67 | -60 | 60 |
| 7 | Ireland | 8 | 77 | -69 | 69 |
| 8 | Philippines | 9 | 2 | 7 | 7 |
| 9 | Belgium | 10 | 98 | -88 | 88 |
| 10 | Switzerland | 11 | 116 | -105 | 105 |
| 11 | Germany | 12 | 117 | -105 | 105 |
| 12 | New Zealand | 13 | 38 | -25 | 25 |
| 13 | Netherlands | 14 | 72 | -58 | 58 |
| 14 | Latvia | 15 | 60 | -45 | 45 |
| 15 | France | 16 | 96 | -80 | 80 |
| 16 | Burundi | 17 | 141 | -124 | 124 |
| 17 | South Africa | 18 | 103 | -85 | 85 |
| 18 | Canada | 19 | 23 | -4 | 4 |
| 19 | United States of America | 20 | 31 | -11 | 11 |
| 20 | Ecuador | 21 | 109 | -88 | 88 |
| 21 | Bulgaria | 22 | 53 | -31 | 31 |
| 22 | Slovenia | 23 | 78 | -55 | 55 |
| 23 | Australia | 24 | 18 | 6 | 6 |
| 24 | Moldova | 25 | 68 | -43 | 43 |
| 25 | United Kingdom | 26 | 42 | -16 | 16 |
| 26 | Mozambique | 27 | 61 | -34 | 34 |
| 27 | Luxembourg | 28 | 107 | -79 | 79 |
| 28 | Spain | 29 | 88 | -59 | 59 |
| 29 | Cuba | 30 | 26 | 4 | 4 |
| 30 | Argentina | 31 | 102 | -71 | 71 |
| 31 | Belarus | 32 | 70 | -38 | 38 |
| 32 | Barbados | 33 | 55 | -22 | 22 |
| 33 | Malawi | 34 | 92 | -58 | 58 |
| 34 | The Bahamas | 35 | 36 | -1 | 1 |
| 35 | Austria | 36 | 82 | -46 | 46 |
| 36 | Kenya | 37 | 9 | 28 | 28 |
| 37 | Lesotho | 38 | 43 | -5 | 5 |
| 38 | Portugal | 39 | 95 | -56 | 56 |
| 39 | Namibia | 40 | 112 | -72 | 72 |
| 40 | Madagascar | 41 | 99 | -58 | 58 |
| 41 | Mongolia | 42 | 71 | -29 | 29 |
| 42 | Kazakhstan | 43 | 44 | -1 | 1 |
| 43 | Lithuania | 44 | 65 | -21 | 21 |
| 44 | Peru | 45 | 97 | -52 | 52 |
| 45 | Panama | 46 | 39 | 7 | 7 |
| 46 | Tanzania | 47 | 16 | 31 | 31 |
| 47 | Costa Rica | 48 | 129 | -81 | 81 |
| 48 | Trinidad and Tobago | 49 | 24 | 25 | 25 |
| 49 | Cape Verde | 50 | 136 | -86 | 86 |
| 50 | Botswana | 51 | 46 | 5 | 5 |
| 51 | Jamaica | 52 | 21 | 31 | 31 |
| 52 | Colombia | 53 | 63 | -10 | 10 |
| 53 | Serbia | 54 | 62 | -8 | 8 |
| 54 | Croatia | 55 | 86 | -31 | 31 |
| 55 | Ukraine | 56 | 79 | -23 | 23 |
| 56 | Poland | 57 | 84 | -27 | 27 |
| 57 | Bolivia | 58 | 128 | -70 | 70 |
| 58 | Singapore | 59 | 8 | 51 | 51 |
| 59 | Laos | 60 | 137 | -77 | 77 |
| 60 | Thailand | 61 | 11 | 50 | 50 |
| 61 | Estonia | 62 | 94 | -32 | 32 |
| 62 | Zimbabwe | 63 | 35 | 28 | 28 |
| 63 | Guyana | 64 | 134 | -70 | 70 |
| 64 | Israel | 65 | 34 | 31 | 31 |
| 65 | Chile | 66 | 47 | 19 | 19 |
| 66 | Kyrgyzstan | 67 | 51 | 16 | 16 |
| 67 | Bangladesh | 68 | 64 | 4 | 4 |
| 68 | Italy | 69 | 105 | -36 | 36 |
| 69 | Republic of Macedonia | 70 | 125 | -55 | 55 |
| 70 | Brazil | 71 | 57 | 14 | 14 |
| 71 | Romania | 72 | 54 | 18 | 18 |
| 72 | Honduras | 73 | 131 | -58 | 58 |
| 73 | Montenegro | 74 | 81 | -7 | 7 |
| 74 | Russia | 75 | 52 | 23 | 23 |
| 75 | Vietnam | 76 | 29 | 47 | 47 |
| 76 | Senegal | 77 | 119 | -42 | 42 |
| 77 | Dominican Republic | 78 | 22 | 56 | 56 |
| 78 | Sri Lanka | 79 | 80 | -1 | 1 |
| 79 | Mexico | 80 | 45 | 35 | 35 |
| 80 | Paraguay | 81 | 132 | -51 | 51 |
| 81 | Uruguay | 82 | 135 | -53 | 53 |
| 82 | Albania | 83 | 115 | -32 | 32 |
| 83 | El Salvador | 84 | 113 | -29 | 29 |
| 84 | Georgia | 85 | 91 | -6 | 6 |
| 85 | Venezuela | 86 | 12 | 74 | 74 |
| 86 | People's Republic of China | 87 | 13 | 74 | 74 |
| 87 | Uganda | 88 | 20 | 68 | 68 |
| 88 | Guatemala | 89 | 120 | -31 | 31 |
| 89 | Slovakia | 90 | 56 | 34 | 34 |
| 90 | Greece | 91 | 83 | 8 | 8 |
| 91 | Swaziland | 92 | 14 | 78 | 78 |
| 92 | Hungary | 93 | 66 | 27 | 27 |
| 93 | Azerbaijan | 94 | 106 | -12 | 12 |
| 94 | Cyprus | 95 | 111 | -16 | 16 |
| 95 | Czech Republic | 96 | 87 | 9 | 9 |
| 96 | Indonesia | 97 | 17 | 80 | 80 |
| 97 | Brunei | 98 | 14 | 84 | 84 |
| 98 | Malta | 99 | 122 | -23 | 23 |
| 99 | Belize | 100 | 40 | 60 | 60 |
| 100 | Ghana | 101 | 133 | -32 | 32 |
| 101 | Tajikistan | 102 | 85 | 17 | 17 |
| 102 | Armenia | 103 | 126 | -23 | 23 |
| 103 | Japan | 104 | 4 | 100 | 100 |
| 104 | Maldives | 105 | 101 | 4 | 4 |
| 105 | Mauritius | 106 | 6 | 100 | 100 |
| 106 | Malaysia | 107 | 5 | 102 | 102 |
| 107 | Cambodia | 108 | 30 | 78 | 78 |
| 108 | Suriname | 109 | 74 | 35 | 35 |
| 109 | Burkina Faso | 110 | 138 | -28 | 28 |
| 110 | Liberia | 111 | 50 | 61 | 61 |
| 111 | Nepal | 112 | 3 | 109 | 109 |
| 112 | Kuwait | 113 | 114 | -1 | 1 |
| 113 | India | 114 | 19 | 95 | 95 |
| 114 | United Arab Emirates | 115 | 118 | -3 | 3 |
| 115 | Qatar | 116 | 139 | -23 | 23 |
| 116 | South Korea | 117 | 1 | 116 | 116 |
| 117 | Nigeria | 118 | 92 | 26 | 26 |
| 118 | Zambia | 119 | 127 | -8 | 8 |
| 119 | Bhutan | 120 | 33 | 87 | 87 |
| 120 | Angola | 121 | 90 | 31 | 31 |
| 121 | Fiji | 122 | 104 | 18 | 18 |
| 122 | Tunisia | 123 | 110 | 13 | 13 |
| 123 | Bahrain | 124 | 6 | 118 | 118 |
| 124 | Turkey | 125 | 41 | 84 | 84 |
| 125 | Algeria | 126 | 75 | 51 | 51 |
| 126 | Ethiopia | 127 | 10 | 117 | 117 |
| 127 | Oman | 128 | 28 | 100 | 100 |
| 128 | Egypt | 129 | 48 | 81 | 81 |
| 129 | Saudi Arabia | 130 | 123 | 7 | 7 |
| 130 | Mauritania | 131 | 142 | -11 | 11 |
| 131 | Guinea | 132 | 140 | -8 | 8 |
| 132 | Morocco | 133 | 100 | 33 | 33 |
| 133 | Jordan | 134 | 108 | 26 | 26 |
| 134 | Lebanon | 135 | 76 | 59 | 59 |
| 135 | Côte d'Ivoire | 136 | 130 | 6 | 6 |
| 136 | Iran | 137 | 69 | 68 | 68 |
| 137 | Mali | 138 | 124 | 14 | 14 |
| 138 | Syria | 139 | 121 | 18 | 18 |
| 139 | Chad | 140 | 37 | 103 | 103 |
| 140 | Pakistan | 141 | 27 | 114 | 114 |
| 141 | Yemen | 142 | 88 | 54 | 54 |
Preeliminary results available in a blog format
editAt [12]. @Nemo bis and GerardM:. We are very curious what you think (don't hesitate to be critical). What we would really appreciate would be any alternative hypothesis (to the one presented) that could try to explain why post-1950s Confucian and South Asian clusters seem so much more inclusive of female biographies than others (including the "Western" clusters). Are we seeing a data error, or something else - and if so, what? --Piotrus (talk) 10:53, 8 January 2015 (UTC)
- I've read the blog post now. (Nice that you managed to get feedback in several other venues, by the way.)
- The first thing is that when I look at [13] I see something different: a big cluster of wikis around the line between Belarusian and Japanese; and then most "top 10" Wikipedias almost perfectly aligned on the same horizontal line.
- The second is that I'm not so convinced by the aggregation [14]. It does make a difference whether a topic is covered in 1 or 10 southern/northern Europe languages. The graph is biased in favour of the subjects Wikipedia considers less important and has covered in less languages: this seems absurd. I'd rather try doing the opposite, for instance exclude all the biographies which exist in less than N languages: it does matter to me why some languages don't cover Cornelia; way less how many localistic biographies on Nth division male soccer players one or the other wiki has (it.wiki could have 200k more soccer players and that would change the stats dramatically, but not the substance).
- Finally, yes, I don't trust the data at all. It's entirely possible that the outliers are simply incorrect data. I see you have around 300k "gendered biographies" from it.wiki; well, there are 250k in total, so that's almost-complete data we imported. The biggest European languages have a lot of overlap, so they helped each other on Wikidata because each piece of data on each entry had multiple chances of being imported: I trust their data more (and see point 1). Isolated entries are likely to be incomplete or incorrect, and you end up considering "about 35% of total records" which gives huge margins for error, likely biased (see point 2).
- This is a ginepraio. When the numbers are so small, there are infinite sources of mistakes. No wiki, except it.wiki, has 100 % complete person data; only en.wiki and de.wiki has some spotty persondata; all the others have unstructured biographies. Structured info was in infoboxes, but infoboxes are not evenly distributed and were not evenly imported in Wikidata. To assess the data you should go check every wiki, one by one, to ensure that they don't have a bias toward infobox-ing volleyball players rather than opera singers rather than members of parliament rather than porn actors; and then you should go check whether that bias was reproduced on Wikidata, or maybe Wikidata imports added new ones by selecting a subset of infoboxes or properties or by making mistakes.
- Perhaps, by drastically reducing the dataset (at least by one order of magnitude) per point 2, you can reach a 90+ % coverage of DOB+culture+gender and see how much the results change. If nothing changes, then point 3 may be moot and point 4 unnecessary, so we would be left with the point 1 dilemma (perhaps cultural colonialism of English articles being translated in European languages, but not Chinese and Japanese? cf. the three scandinavian languages forming a triangle, probably reinforced by reciprocal translations). --Nemo 21:24, 11 January 2015 (UTC)
![[13]](http://notconfusing.com/wp-content/uploads/2015/01/Language_femper_Scatter1.png){kind=link}
![[14]](http://notconfusing.com/wp-content/uploads/2015/01/language_aggregate_femper.png){kind=link}
Early paper draft ready
editOur Google Docs linked in #Key links is at the point I call early complete draft. It still needs copyediting, some fixes here and there, but it has the gist of the findings, all the sections, discussion, conclusions, etc. Any comments as always highly appreciated. We need to cut down from 10k to 8k words, so feel free to tell us which parts seem not relevant. @Nemo bis: --Piotrus (talk) 23:18, 28 January 2015 (UTC)
Is it offensive when men call women 'females'?
editsee: http://kerbev.hubpages.com/hub/calling-women-females Ottawahitech (talk) 23:58, 11 August 2015 (UTC)